
【CDK】Glue Python Shellで自作関数を用いる方法
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
データ事業本部ビッグデータチームのkasamaです。
今回はGlue Python Shell Job Typeで自作関数を使用する実装をCDKで行いたいと思います。
前提
今回実現したい構成は以下になります。
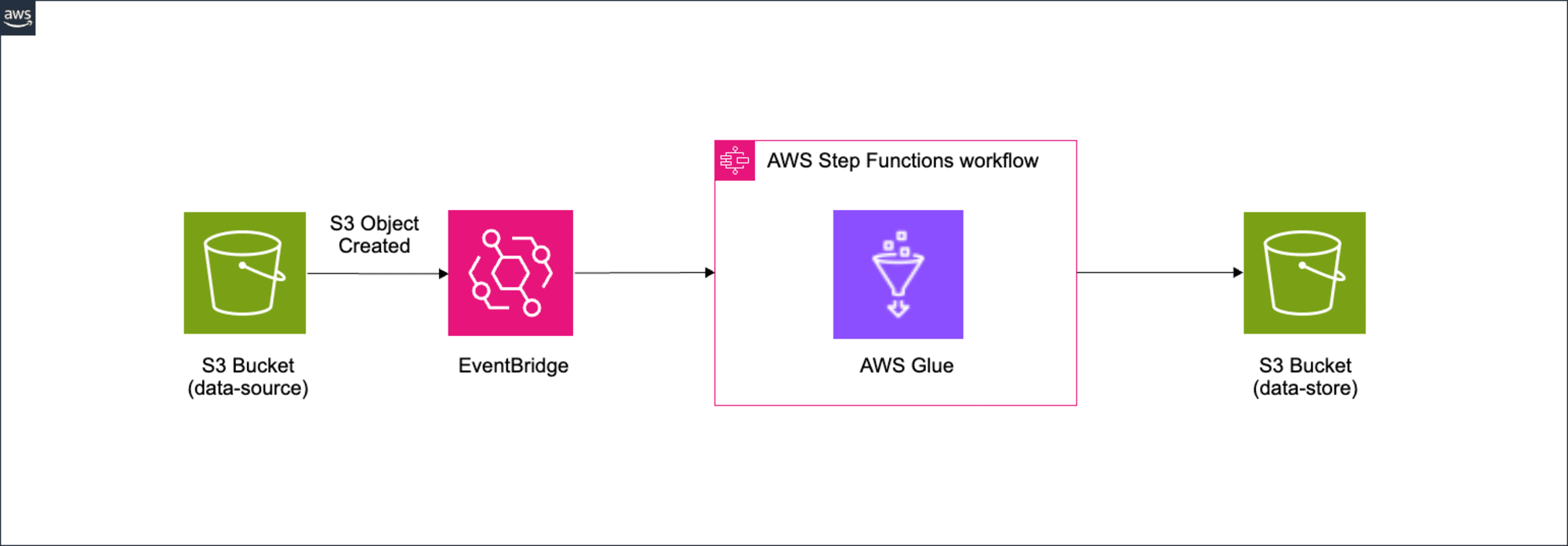
- EventBridgeでdata-source BucketへのObject Createdイベントを検知し、Step Functionsを起動します。
- Step Functions内でGlue Jobを実行します。
- Glue Jobでデータ加工した出力先としてdata-store Bucketにcsvファイルを生成します。
加工処理前のcsvファイルの中身になります。
"animal_id","animal_name","species","weight_kg","age_years","habitat","arrival_year"
"001","Luna","Tiger","120","5","Savanna","2018"
"002","Bella","Elephant","2500","8","Jungle","2015"
"003","Max","Lion","190","6","Savanna","2017"
"004","Daisy","Giraffe","800","4","Savanna","2019"
"005","Charlie","Rhino","2300","7","Jungle","2016"
今回の実装コードについては、Github上に格納してあるのでご確認いただければと思います。ブログ内ではGlueに関連する実装に限定します。
@ 40_glue_common_component_with_cdk % tree
.
├── README.md
├── cdk
│ ├── bin
│ │ └── app.ts
│ ├── cdk.json
│ ├── jest.config.js
│ ├── lib
│ │ ├── constructs
│ │ │ ├── eventbridge.ts
│ │ │ ├── glue.ts
│ │ │ ├── s3.ts
│ │ │ └── step-functions.ts
│ │ └── stack
│ │ └── etl-stack.ts
│ ├── package-lock.json
│ ├── package.json
│ ├── parameter.ts
│ ├── test
│ │ └── app.test.ts
│ └── tsconfig.json
├── package-lock.json
└── resources
├── common
│ ├── data_processing.py
│ └── get_logger.py
└── glue-jobs
└── etl_script.py
10 directories, 18 files
Glue上で使用する自作のライブラリとしては、common配下のdata_processing.pyとget_logger.pyになります。方法としては、以下になります。
- pythonファイルを
--extra-py-filesパラメータ指定 - S3にUploadする際にzip化し、zipファイルを
--extra-py-filesパラメータ指定 - S3にUploadする際にegg化し、eggファイルを
--extra-py-filesパラメータ指定 - S3にUploadする際にwhl化し、whlファイルを
--extra-py-filesパラメータ指定
公式の記載では、eggまたはWhlファイルでを指定するように記載されています。今回はeggファイル以外の方法で試してみたいと思います。
結論
以下の表は、AWS Glueジョブで外部Pythonライブラリを使用する際の各アプローチの特徴をまとめたものです。
| アプローチ | 利点 | 欠点 | 推奨される使用場面 |
|---|---|---|---|
| Pythonファイル直接指定 | • シンプル • 迅速な変更とテストが可能 • 特別なビルドプロセス不要 |
• 大規模プロジェクトでは管理が困難 • 依存関係の管理が複雑 |
• 小規模プロジェクト • 開発段階 • 迅速なプロトタイピング |
| .zipファイル | • 比較的シンプル • 特別なビルドプロセス不要 • 複数ファイルをまとめて管理可能 |
• 依存関係の管理が難しい場合がある • バイナリファイルの扱いに制限 |
• 中規模プロジェクト • ビルドプロセスを避けたい場合 |
| .eggファイル | • レガシーシステムとの親和性 | • 新しいプロジェクトでは非推奨 | • レガシーシステム |
| .whlファイル | • 現行のPythonパッケージング標準 • 高速インストール • Python 2.xと3.xの両対応 |
• 初期設定に若干の手間が必要 | • 新規プロジェクト • 大規模プロジェクト • 長期的なメンテナンスが必要なプロジェクト |
この表を参考に、プロジェクトの規模、要件、開発チームの習熟度に応じて最適なアプローチを選択することができます。Pythonファイルを直接指定する方法は、最もシンプルで開発中の迅速な変更とテストに適していますが、大規模プロジェクトでは管理が困難になる可能性があります。zipファイルはシンプルで直感的、特別なビルドプロセスが不要という利点がありますが、外部ライブラリの依存関係の管理が難しい場合があります。eggファイルは新しいプロジェクトでは推奨されません。whlファイルの使用はPythonパッケージング標準であり、インストールが高速で、Python 2.xと3.xの両方に対応しています。また、ビルド済みのバイナリを含められる利点もあります。
プロジェクトの規模や要件、開発チームの習熟度に応じて最適なアプローチを選択することが重要です。新規や大規模プロジェクトでは.whlファイルが最適ですが、小規模プロジェクトや開発段階ではPythonファイルの直接指定が便利な場合もあります。特別なビルドプロセスを避けたい場合は.zipファイルも検討できます。
pythonファイルを指定する方法
実装
import { Construct } from "constructs";
import * as glue from "aws-cdk-lib/aws-glue";
import * as iam from "aws-cdk-lib/aws-iam";
export interface GlueConstructProps {
envName: string;
projectName: string;
dataSourceBucketName: string;
dataStoreBucketName: string;
sysBucketName: string;
}
export class GlueConstruct extends Construct {
public readonly glueJobName: string;
constructor(scope: Construct, id: string, props: GlueConstructProps) {
super(scope, id);
const glueJobRole = new iam.Role(this, "GlueJobRole", {
assumedBy: new iam.ServicePrincipal("glue.amazonaws.com"),
description: "Role for Glue Job execution",
roleName: `${props.projectName}-${props.envName}-etl-glue-execution-role`,
});
glueJobRole.addToPolicy(
new iam.PolicyStatement({
resources: ["arn:aws:logs:*:*:*:/aws-glue/*"],
actions: [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
],
})
);
glueJobRole.addToPolicy(
new iam.PolicyStatement({
actions: [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"s3:CopyObject",
],
resources: [
`arn:aws:s3:::${props.dataSourceBucketName}`,
`arn:aws:s3:::${props.dataSourceBucketName}/*`,
`arn:aws:s3:::${props.dataStoreBucketName}`,
`arn:aws:s3:::${props.dataStoreBucketName}/*`,
`arn:aws:s3:::${props.sysBucketName}`,
`arn:aws:s3:::${props.sysBucketName}/*`,
],
})
);
this.glueJobName = `${props.projectName}-${props.envName}-glue-job`;
// Glue Jobの定義
new glue.CfnJob(this, "GlueJob", {
name: this.glueJobName,
role: glueJobRole.roleArn,
command: {
name: "pythonshell",
pythonVersion: "3.9",
scriptLocation: `s3://${props.sysBucketName}/glue-jobs/etl_script.py`,
},
executionProperty: {
maxConcurrentRuns: 5,
},
defaultArguments: {
"--TempDir": `s3://${props.sysBucketName}/tmp`,
"--job-language": "python",
"--extra-py-files": `s3://${props.sysBucketName}/common/data_processing.py,s3://${props.sysBucketName}/common/get_logger.py`,
"--S3_OUTPUT_BUCKET": props.dataStoreBucketName,
"--S3_OUTPUT_KEY": `output/`,
},
});
}
}
--extra-py-filesパラメータとして、sys Bucketのpythonファイル名をカンマ区切りで指定します。
import pandas as pd
from io import StringIO
from datetime import datetime
from zoneinfo import ZoneInfo
from get_logger import setup_logging
logger = setup_logging()
def get_current_time():
current_time = datetime.now(ZoneInfo("Asia/Tokyo"))
logger.info(f"Current time: {current_time}")
return current_time
def calculate_years_in_zoo(df, arrival_year_column):
logger.info(f"Calculating years in zoo based on column: {arrival_year_column}")
current_year = get_current_time().year
df["years_in_zoo"] = current_year - df[arrival_year_column]
logger.info(f"Years in zoo calculated. Added 'years_in_zoo' column.")
return df
def categorize_age(df, age_column="age_years"):
logger.info(f"Categorizing age based on column: {age_column}")
def get_age_category(age):
if age < 5:
return "Young"
elif age < 10:
return "Adult"
else:
return "Senior"
df["age_category"] = df[age_column].apply(get_age_category)
logger.info("Age categorization complete. Added 'age_category' column.")
return df
def read_csv_from_s3(s3_client, bucket, key):
logger.info(f"Reading CSV from S3. Bucket: {bucket}, Key: {key}")
response = s3_client.get_object(Bucket=bucket, Key=key)
df = pd.read_csv(response["Body"])
logger.info(f"Successfully read CSV. Shape: {df.shape}")
return df
def write_csv_to_s3(s3_client, df, bucket, key):
logger.info(f"Writing CSV to S3. Bucket: {bucket}, Key: {key}")
csv_buffer = StringIO()
df.to_csv(csv_buffer, index=False)
s3_client.put_object(Bucket=bucket, Key=key, Body=csv_buffer.getvalue())
logger.info("Successfully wrote CSV to S3.")
def process_data(df):
logger.info("Starting data processing")
logger.info(f"Input data shape: {df.shape}")
df = calculate_years_in_zoo(df, "arrival_year")
df = categorize_age(df, "age_years")
logger.info(f"Processed data shape: {df.shape}")
logger.info("Data processing complete")
return df
S3への書き込み、読み込み、データ加工、現在時刻取得処理などを共通関数として実装しています。
import logging
import sys
def setup_logging():
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# Remove existing handlers
for handler in logger.handlers[:]:
logger.removeHandler(handler)
log_format = "[%(levelname)s][%(filename)s][%(funcName)s:%(lineno)d]\t%(message)s"
formatter = logging.Formatter(log_format)
stdout_handler = logging.StreamHandler(stream=sys.stdout)
stdout_handler.setFormatter(formatter)
logger.addHandler(stdout_handler)
return logger
共通関数としてloggerの設定を定義しています。
import sys
import pkgutil
import glob
import boto3
import traceback
def print_importable_modules():
print("--- Importable Python Modules ---")
for module in pkgutil.iter_modules():
print(module.name)
print_importable_modules()
from data_processing import process_data, get_current_time, read_csv_from_s3, write_csv_to_s3
from get_logger import setup_logging
from awsglue.utils import getResolvedOptions
logger = setup_logging()
def main():
try:
args = getResolvedOptions(
sys.argv,
[
"S3_INPUT_BUCKET",
"S3_INPUT_KEY",
"S3_OUTPUT_BUCKET",
"S3_OUTPUT_KEY_PREFIX",
],
)
s3_input_bucket = args["S3_INPUT_BUCKET"]
s3_input_key = args["S3_INPUT_KEY"]
s3_output_bucket = args["S3_OUTPUT_BUCKET"]
s3_output_key = args["S3_OUTPUT_KEY_PREFIX"]
logger.info(f"Reading input data from s3://{s3_input_bucket}/{s3_input_key}")
s3_client = boto3.client("s3")
input_data = read_csv_from_s3(s3_client, s3_input_bucket, s3_input_key)
logger.info("Processing data...")
processed_data = process_data(input_data)
current_time = get_current_time().strftime("%Y-%m-%d-%H-%M-%S")
output_filename = f"{s3_output_key}output_{current_time}.csv"
logger.info(f"Writing processed data to s3://{s3_output_bucket}/{output_filename}")
write_csv_to_s3(s3_client, processed_data, s3_output_bucket, output_filename)
logger.info("ETL process completed successfully")
except Exception as e:
logger.error(f"Unexpected error: {str(e)}")
logger.error(traceback.format_exc())
raise e
if __name__ == "__main__":
main()
importできるmoduleを標準出力し、Glueのoutput.logで確認できるようにしています。その後は共通関数を用いて、S3からのデータ取得、加工処理、S3へのデータUpload処理を行っています。
デプロイ
それではデプロイ作業を実施します。
package.jsonがあるディレクトリで依存関係をインストールします。
npm install
次にcdk.jsonがあるディレクトリで、CDKで定義されたリソースのコードをAWS CloudFormationテンプレートに合成(変換)するプロセスを実行します。
npx cdk synth --profile <YOUR_AWS_PROFILE>
同じくcdk.jsonがあるディレクトリでデプロイコマンドを実行します。--allはCDKアプリケーションに含まれる全てのスタックをデプロイするためのオプション、--require-approval neverはセキュリティ的に敏感な変更やIAMリソースの変更を含むデプロイメント時の承認を求めるダイアログ表示を完全にスキップします。neverは、どんな変更でも事前確認なしにデプロイすることを意味します。今回は検証用なので指定していますが、慎重にデプロイする場合は必要のないオプションになるかもしれません。
npx cdk deploy --all --require-approval never --profile <YOUR_AWS_PROFILE>
実行
EventBridge Triggerでの実行ですので、実際にS3にファイルを格納し、実行しました。
Glue Jobが正しく動作し、Logging処理やデータ加工処理が実行されていることもlogから確認できました。
2024-07-09T12:58:11.593Z
EXTRA_PY_FILES = s3://cm-kasama-dev-sys/common/data_processing.py,s3://cm-kasama-dev-sys/common/get_logger.py file = s3://cm-kasama-dev-sys/common/data_processing.py,s3://cm-kasama-dev-sys/common/get_logger.py
2024-07-09T12:58:11.612Z
file to download from: s3://cm-kasama-dev-sys/common/data_processing.py
2024-07-09T12:58:11.614Z
downloading s3:// cm-kasama-dev-sys/common/data_processing.py; attempt: 0...
2024-07-89T12:58:12.438Z
Completed 2.0 KiB/2.0 KiB (28.2 KiB/s) with 1 file(s) remaining
2024-07-09T12:58:12.441Z
download: s3://cm-kasama-dev-sys/common/data_processing.py to glue-python-libs-uMOB/data_processing.py
2024-07-09T12:58:12.596Z
downloaded s3:// cm-kasama-dev-sys/comnon/data_processing.py.
2024-07-09T12:58:12.604Z
file to donnload from: s3://cm-kasama-dev-sys/common/get_logger.py
2024-07-09T12:58:12.605Z
downloading s3://cm-kasama-dev-sys/common/get_logger.py; attempt: 0...
2024-07-0912:58:13.4962
Completed 522 Bytes/522 Bytes (4.7 KiB/s) with 1 file(s) remaining
2024-07-09T12:58:13.502Z
download: s3:// cm-kasama-dev-sys/common/get_logger.py to glue-python-libs-uMOB/get_logger.py
2024-07-09T12:58:13.643Z
downloaded s3:// cm-kasama-dev-sys/common/get_logger.py.
2024-07-0912:58:13.643Z
Setting python runtime env to 3.9 analytics (default)
2024-07-09T12:58:13.808Z
Setup complete. Starting script execution: ---
2024-07-0912:58:18.493Z
--- Importable Python Modules ---
awsglue
data_processing
get_logger
blueprint-run-script
runscript
:
:
2024-07-09T12:58:18.676Z
[INFO] [data_processing-py](read_csv_from_s3:41) Reading CSV from $3. Bucket: cm-kasoma-dev-data-source, Key: input/animal_info.csv
2024-07-09T12:58:18.806Z
[INFO] [data_processing.pyl [read_csv_from_s3:44] Successfully read CSV. Shape: (5, 7)
2024-07-09T12:58:18.806Z
[INFO] [etl_script.py][main:53] Processing data... [INFO][data_processing.py][process_data:57] Starting data processing
2024-07-09T12:58:18.806Z
[INFO] [data_processing-py] [process_data:58] Input data shape: (5, 7) (INFO][data_processing.py][calculate_years_in_zoo:17] Calculating years in zoo based on column: arrival_year
2024-07-09T12:58:18.880Z
[INFO] [data_processing.py][get_current_time:12] Current time: 2024-07-89 21:58:18.880261+09:00
2024-07-09T12:58:18.887Z
[INFO] [data_processing-py] [calculate_years_in_zoo:20] Years in zoo calculated. Added 'years_in_zoo' column. [INFO][data_processing-py][categorize_age:25] Categorizing age based on column: age_years
2024-07-09T12:58:18.888Z
[INFO] [data_processing.py][categorize_age:36] Age categorization complete. Added 'age_category' column.
2024-07-09T12:58:18.888Z
[INFO] [data_processing.py][process_data:63] Processed data shape: (5, 9) [INFO][data_processing.pyJprocess_data:64] Data processing complete [INFO] [data_processing.pyj[get_current_time:12] Current time: 2024-07-89
2024-07-09T12:58:18.994Z
[INFO] [data_processing.py][write_csv_to_s3:53] Successfully wrote CSV to S3. [INFO][etl_script.py][main:62] ETL process completed successfully
store Bucketに出力されたcsvも加工された状態であることを確認しました。
animal_id,animal_name,species,weight_kg,age_years,habitat,arrival_year,years_in_zoo,age_category
1,Luna,Tiger,120,5,Savanna,2018,6,Adult
2,Bella,Elephant,2500,8,Jungle,2015,9,Adult
3,Max,Lion,190,6,Savanna,2017,7,Adult
4,Daisy,Giraffe,800,4,Savanna,2019,5,Young
zipファイルを指定する方法
実装
先ほどからの変更点のみ記載します。
import * as cdk from "aws-cdk-lib";
+import { Asset } from "aws-cdk-lib/aws-s3-assets";
import * as path from "path";
import {
Bucket,
BlockPublicAccess,
BucketEncryption,
} from "aws-cdk-lib/aws-s3";
import { Construct } from "constructs";
export interface S3ConstructProps {
envName: string;
projectName: string;
}
export class S3Construct extends Construct {
public readonly dataSourceBucket: Bucket;
public readonly dataStoreBucket: Bucket;
public readonly sysBucket: Bucket;
+ public readonly commonZipAsset: Asset;
constructor(scope: Construct, id: string, props: S3ConstructProps) {
super(scope, id);
this.dataSourceBucket = new Bucket(this, "DataSourceBucket", {
bucketName: `${props.projectName}-${props.envName}-data-source`,
removalPolicy: cdk.RemovalPolicy.DESTROY,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
encryption: BucketEncryption.KMS_MANAGED,
versioned: true,
eventBridgeEnabled: true,
});
this.dataStoreBucket = new Bucket(this, "DataStoreBucket", {
bucketName: `${props.projectName}-${props.envName}-data-store`,
removalPolicy: cdk.RemovalPolicy.DESTROY,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
encryption: BucketEncryption.KMS_MANAGED,
versioned: true,
});
this.sysBucket = new Bucket(this, "SysBucket", {
bucketName: `${props.projectName}-${props.envName}-sys`,
removalPolicy: cdk.RemovalPolicy.DESTROY,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
encryption: BucketEncryption.KMS_MANAGED,
versioned: true,
eventBridgeEnabled: true,
});
// Glue スクリプトを S3 バケットにデプロイ
new cdk.aws_s3_deployment.BucketDeployment(this, "DeployGlueScript", {
sources: [cdk.aws_s3_deployment.Source.asset("../resources/glue-jobs")],
// sources: [cdk.aws_s3_deployment.Source.asset("../resources")],
destinationBucket: this.sysBucket,
destinationKeyPrefix: "glue-jobs/",
});
// common ディレクトリを zip として Asset にデプロイ
+ this.commonZipAsset = new Asset(this, "CommonZipAsset", {
+ path: path.join(__dirname, "..", +"..", "..", "resources", "common"),
+ });
// common.zip を sysBucket にコピー
+ new cdk.aws_s3_deployment.BucketDeployment(this, "DeployCommonZip", {
+ sources: [
+ cdk.aws_s3_deployment.Source.bucket(
+ this.commonZipAsset.bucket,
+ this.commonZipAsset.s3ObjectKey
+ ),
+ ],
+ destinationBucket: this.sysBucket,
+ destinationKeyPrefix: "common/",
+ extract: false,
+ });
}
}
先ほどからの変更点として、commonZipAssetを
publicで参照できるように宣言するのとS3 Bucketにzipファイルをデプロイする処理に実装しています。
this.commonZipAsset = new Asset(this, "CommonZipAsset", {
path: path.join(__dirname, "..", "..", "..", "resources", "common"),
});
Assetクラスを使用して、ローカルのcommonディレクトリをCDKのAssetとして定義しています。
path.join()を使用して、現在のディレクトリからresources/commonディレクトリへのパスを指定しています。
このAssetは、デプロイ時に自動的にZipファイルに圧縮され、一時的なS3バケットにアップロードされます。
new cdk.aws_s3_deployment.BucketDeployment(this, "DeployCommonZip", {
sources: [
cdk.aws_s3_deployment.Source.bucket(
this.commonZipAsset.bucket,
this.commonZipAsset.s3ObjectKey
),
],
destinationBucket: this.sysBucket,
destinationKeyPrefix: "common/",
extract: false,
});
BucketDeploymentクラスを使用して、Assetとして作成したZipファイルを目的のS3バケットにデプロイしています。
extract: falseを指定することで、Zipファイルをそのままの状態でコピーし、展開しないようにしています。
この実装により、ローカルのcommonディレクトリの内容がZipファイルとして圧縮され、指定されたS3バケットのcommonプレフィックス配下にデプロイされます。
import { Construct } from "constructs";
import * as glue from "aws-cdk-lib/aws-glue";
import * as iam from "aws-cdk-lib/aws-iam";
export interface GlueConstructProps {
envName: string;
projectName: string;
dataSourceBucketName: string;
dataStoreBucketName: string;
sysBucketName: string;
+ commonZipkey: string;
}
export class GlueConstruct extends Construct {
public readonly glueJobName: string;
constructor(scope: Construct, id: string, props: GlueConstructProps) {
super(scope, id);
const glueJobRole = new iam.Role(this, "GlueJobRole", {
assumedBy: new iam.ServicePrincipal("glue.amazonaws.com"),
description: "Role for Glue Job execution",
roleName: `${props.projectName}-${props.envName}-etl-glue-execution-role`,
});
glueJobRole.addToPolicy(
new iam.PolicyStatement({
resources: ["arn:aws:logs:*:*:*:/aws-glue/*"],
actions: [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
],
})
);
glueJobRole.addToPolicy(
new iam.PolicyStatement({
actions: [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"s3:CopyObject",
],
resources: [
`arn:aws:s3:::${props.dataSourceBucketName}`,
`arn:aws:s3:::${props.dataSourceBucketName}/*`,
`arn:aws:s3:::${props.dataStoreBucketName}`,
`arn:aws:s3:::${props.dataStoreBucketName}/*`,
`arn:aws:s3:::${props.sysBucketName}`,
`arn:aws:s3:::${props.sysBucketName}/*`,
],
})
);
this.glueJobName = `${props.projectName}-${props.envName}-glue-job`;
// Glue Jobの定義
new glue.CfnJob(this, "GlueJob", {
name: this.glueJobName,
role: glueJobRole.roleArn,
command: {
name: "pythonshell",
pythonVersion: "3.9",
scriptLocation: `s3://${props.sysBucketName}/glue-jobs/etl_script.py`,
},
executionProperty: {
maxConcurrentRuns: 5,
},
defaultArguments: {
"--TempDir": `s3://${props.sysBucketName}/tmp`,
"--job-language": "python",
+ "--extra-py-files": `s3://${props.sysBucketName}/common/${props.commonZipkey}`,
"--S3_OUTPUT_BUCKET": props.dataStoreBucketName,
"--S3_OUTPUT_KEY": `output/`,
},
});
}
}
glue.tsの先ほどからの変更点としては、2点です。1点目はPropsとして、commonZipkeyを受け取る指定に修正、2点目はその値を用いて、--extra-py-filesを指定する形に修正しています。これはzipファイルがcdkでデプロイされるタイミングで任意のファイル名でzip化されるため、ファイル名を変数として指定する必要があるためです。
import { Construct } from "constructs";
import * as cdk from "aws-cdk-lib";
import { S3Construct } from "../constructs/s3";
import { GlueConstruct, GlueConstructProps } from "../constructs/glue";
import {
StepFunctionsConstruct,
StepFunctionsConstructProps,
} from "../constructs/step-functions";
import {
EventBridgeConstruct,
EventBridgeConstructProps,
} from "../constructs/eventbridge";
export interface ETLStackProps extends cdk.StackProps {
envName: string;
projectName: string;
}
export class ETLStack extends cdk.Stack {
constructor(scope: Construct, id: string, props: ETLStackProps) {
super(scope, id, props);
const s3Construct = new S3Construct(this, "S3", {
envName: props.envName,
projectName: props.projectName,
});
const glueConstruct = new GlueConstruct(this, "Glue", {
envName: props.envName,
projectName: props.projectName,
dataSourceBucketName: s3Construct.dataSourceBucket.bucketName,
dataStoreBucketName: s3Construct.dataStoreBucket.bucketName,
sysBucketName: s3Construct.sysBucket.bucketName,
+ commonZipkey: s3Construct.commonZipAsset.s3ObjectKey,
} as GlueConstructProps);
const stepFunctionsConstruct = new StepFunctionsConstruct(
this,
"StepFunctions",
{
envName: props.envName,
projectName: props.projectName,
dataSourceBucketName: s3Construct.dataSourceBucket.bucketName,
dataStoreBucketName: s3Construct.dataStoreBucket.bucketName,
glueJobName: glueConstruct.glueJobName,
} as StepFunctionsConstructProps
);
new EventBridgeConstruct(this, "EventBridge", {
envName: props.envName,
projectName: props.projectName,
dataSourceBucketName: s3Construct.dataSourceBucket.bucketName,
stateMachineArn: stepFunctionsConstruct.stateMachine.stateMachineArn,
} as EventBridgeConstructProps);
}
}
etl-stack.tsではglueのConstructにcommonZipAsset.s3ObjectKeyを渡すように修正しています。
import sys
import pkgutil
+ import glob
import boto3
import traceback
+ # 動的にZIPファイルを検索し、sys.pathに追加
+ zip_files = glob.glob("/tmp/glue-python-libs-*/*.zip")
+ for zip_file in zip_files:
+ sys.path.append(zip_file)
+ print(f"Added {zip_file} to sys.path")
+ print("Updated sys.path:", sys.path)
def print_importable_modules():
print("--- Importable Python Modules ---")
for module in pkgutil.iter_modules():
print(module.name)
print_importable_modules()
from data_processing import process_data, get_current_time, read_csv_from_s3, write_csv_to_s3
from get_logger import setup_logging
from awsglue.utils import getResolvedOptions
logger = setup_logging()
def main():
try:
args = getResolvedOptions(
sys.argv,
[
"S3_INPUT_BUCKET",
"S3_INPUT_KEY",
"S3_OUTPUT_BUCKET",
"S3_OUTPUT_KEY_PREFIX",
],
)
s3_input_bucket = args["S3_INPUT_BUCKET"]
s3_input_key = args["S3_INPUT_KEY"]
s3_output_bucket = args["S3_OUTPUT_BUCKET"]
s3_output_key = args["S3_OUTPUT_KEY_PREFIX"]
logger.info(f"Reading input data from s3://{s3_input_bucket}/{s3_input_key}")
s3_client = boto3.client("s3")
input_data = read_csv_from_s3(s3_client, s3_input_bucket, s3_input_key)
logger.info("Processing data...")
processed_data = process_data(input_data)
current_time = get_current_time().strftime("%Y-%m-%d-%H-%M-%S")
output_filename = f"{s3_output_key}output_{current_time}.csv"
logger.info(f"Writing processed data to s3://{s3_output_bucket}/{output_filename}")
write_csv_to_s3(s3_client, processed_data, s3_output_bucket, output_filename)
logger.info("ETL process completed successfully")
except Exception as e:
logger.error(f"Unexpected error: {str(e)}")
logger.error(traceback.format_exc())
raise e
if __name__ == "__main__":
main()
etl_script.pyではuploadしたzipファイルをsys.pathにappendする処理を追加しています。sys.pathは、Pythonがmoduleやpackageを検索するディレクトリのリストです。import文を使用してmoduleをロードしようとすると、Pythonはsys.path内のディレクトリを順番に検索します。ZIPファイルをsys.pathに追加することで、そのZIPファイル内のPython moduleやpackageを直接importできるようになります。/tmp/glue-python-libs-/.zip というパスはAWS Glueでジョブの実行時に必要なPythonライブラリを /tmp ディレクトリ内の特定の場所に自動的に展開するためです。このパスは、Glueが提供する一時的なストレージ領域を指しており、ジョブ実行中にアクセス可能です。
実行
デプロイは先ほどと同様のため、スキップしています。同様にEventBridge TriggerでGlue Jobが実行され、問題なく自作関数を使用できました。
2024-07-09T13:50:04.431Z Added /tmp/glue-python-libs-CysL/6e669a3229cfcaac6848e169f557a49c8f416c3fe955b1526e1876a14432dfa9.zip to sys.path
Updated sys.path: ['/glue/lib', '/tmp/glue-python-libs-CysL', '/tmp', '/glue/lib/installation', '/tmp/python39_loaded', '/.pyenv/versions/3.9.10/lib/python39.zip', '/.pyenv/versions/3.9.10/lib/python3.9', '/.pyenv/versions/3.9.10/lib/python3.9/lib-dynload', '/.pyenv/versions/python39_loaded/lib/python3.9/site-packages', '/tmp/glue-python-libs-CysL/6e669a3229cfcaac6848e169f557a49c8f416c3fe955b1526e1876a14432dfa9.zip']
--- Importable Python Modules ---
awsglue
blueprint-run-script
runscript
__future__
:
:
data_processing
get_logger
[INFO][etl_script.py][main:47] Reading input data from s3://cm-kasama-dev-data-source/input/animal_info.csv
[INFO][data_processing.py][read_csv_from_s3:41] Reading CSV from S3. Bucket: cm-kasama-dev-data-source, Key: input/animal_info.csv
[INFO][data_processing.py][read_csv_from_s3:41] Reading CSV from S3. Bucket: cm-kasama-dev-data-source, Key: input/animal_info.csv
2024-07-09T13:50:04.669Z
[INFO][data_processing.py][read_csv_from_s3:44] Successfully read CSV. Shape: (5, 7)
[INFO][etl_script.py][main:53] Processing data...
[INFO][data_processing.py][read_csv_from_s3:44] Successfully read CSV. Shape: (5, 7) [INFO][etl_script.py][main:53] Processing data...
2024-07-09T13:50:04.669Z
[INFO][data_processing.py][process_data:57] Starting data processing
[INFO][data_processing.py][process_data:58] Input data shape: (5, 7)
[INFO][data_processing.py][calculate_years_in_zoo:17] Calculating years in zoo based on column: arrival_year
[INFO][data_processing.py][process_data:57] Starting data processing [INFO][data_processing.py][process_data:58] Input data shape: (5, 7) [INFO][data_processing.py][calculate_years_in_zoo:17] Calculating years in zoo based on column: arrival_year
2024-07-09T13:50:04.672Z
[INFO][data_processing.py][get_current_time:12] Current time: 2024-07-09 22:50:04.671932+09:00
[INFO][data_processing.py][get_current_time:12] Current time: 2024-07-09 22:50:04.671932+09:00
2024-07-09T13:50:04.676Z
[INFO][data_processing.py][calculate_years_in_zoo:20] Years in zoo calculated. Added 'years_in_zoo' column.
[INFO][data_processing.py][calculate_years_in_zoo:20] Years in zoo calculated. Added 'years_in_zoo' column.
2024-07-09T13:50:04.676Z
[INFO][data_processing.py][categorize_age:25] Categorizing age based on column: age_years
[INFO][data_processing.py][categorize_age:25] Categorizing age based on column: age_years
2024-07-09T13:50:04.677Z
[INFO][data_processing.py][categorize_age:36] Age categorization complete. Added 'age_category' column.
[INFO][data_processing.py][categorize_age:36] Age categorization complete. Added 'age_category' column.
2024-07-09T13:50:04.678Z
[INFO][data_processing.py][process_data:63] Processed data shape: (5, 9)
[INFO][data_processing.py][process_data:64] Data processing complete
[INFO][data_processing.py][process_data:63] Processed data shape: (5, 9) [INFO][data_processing.py][process_data:64] Data processing complete
2024-07-09T13:50:04.678Z
[INFO][data_processing.py][get_current_time:12] Current time: 2024-07-09 22:50:04.677611+09:00
[INFO][data_processing.py][get_current_time:12] Current time: 2024-07-09 22:50:04.677611+09:00
2024-07-09T13:50:04.678Z
[INFO][etl_script.py][main:59] Writing processed data to s3://cm-kasama-dev-data-store/output/output_2024-07-09-22-50-04.csv
[INFO][etl_script.py][main:59] Writing processed data to s3://cm-kasama-dev-data-store/output/output_2024-07-09-22-50-04.csv
2024-07-09T13:50:04.678Z
[INFO][data_processing.py][write_csv_to_s3:49] Writing CSV to S3. Bucket: cm-kasama-dev-data-store, Key: output/output_2024-07-09-22-50-04.csv
[INFO][data_processing.py][write_csv_to_s3:49] Writing CSV to S3. Bucket: cm-kasama-dev-data-store, Key: output/output_2024-07-09-22-50-04.csv
2024-07-09T13:50:04.815Z
[INFO][data_processing.py][write_csv_to_s3:53] Successfully wrote CSV to S3.
[INFO][etl_script.py][main:62] ETL process completed successfully
whlファイルを指定する方法
実装
先ほどからの変更点のみ記載します。INPUTのcsvファイルのデータ構造ですが、date型で一部加工処理を行いたいため、arrival_dateカラムに修正しています。
"animal_id","animal_name","species","weight_kg","age_years","habitat","arrival_date"
"001","Luna","Tiger","120","5","Savanna","2018-03-15"
"002","Bella","Elephant","2500","8","Jungle","2015-07-22"
"003","Max","Lion","190","6","Savanna","2017-11-30"
"004","Daisy","Giraffe","800","4","Savanna","2019-01-05"
"005","Charlie","Rhino","2300","7","Jungle","2016-09-10"
import * as cdk from "aws-cdk-lib";
import { Asset } from "aws-cdk-lib/aws-s3-assets";
import * as path from "path";
import {
Bucket,
BlockPublicAccess,
BucketEncryption,
} from "aws-cdk-lib/aws-s3";
import { Construct } from "constructs";
export interface S3ConstructProps {
envName: string;
projectName: string;
}
export class S3Construct extends Construct {
public readonly dataSourceBucket: Bucket;
public readonly dataStoreBucket: Bucket;
public readonly sysBucket: Bucket;
constructor(scope: Construct, id: string, props: S3ConstructProps) {
super(scope, id);
this.dataSourceBucket = new Bucket(this, "DataSourceBucket", {
bucketName: `${props.projectName}-${props.envName}-data-source`,
removalPolicy: cdk.RemovalPolicy.DESTROY,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
encryption: BucketEncryption.KMS_MANAGED,
versioned: true,
eventBridgeEnabled: true,
});
this.dataStoreBucket = new Bucket(this, "DataStoreBucket", {
bucketName: `${props.projectName}-${props.envName}-data-store`,
removalPolicy: cdk.RemovalPolicy.DESTROY,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
encryption: BucketEncryption.KMS_MANAGED,
versioned: true,
});
this.sysBucket = new Bucket(this, "SysBucket", {
bucketName: `${props.projectName}-${props.envName}-sys`,
removalPolicy: cdk.RemovalPolicy.DESTROY,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
encryption: BucketEncryption.KMS_MANAGED,
versioned: true,
eventBridgeEnabled: true,
});
// Glue スクリプトを S3 バケットにデプロイ
new cdk.aws_s3_deployment.BucketDeployment(this, "DeployGlueScript", {
sources: [cdk.aws_s3_deployment.Source.asset("../resources/glue-jobs")],
// sources: [cdk.aws_s3_deployment.Source.asset("../resources")],
destinationBucket: this.sysBucket,
destinationKeyPrefix: "glue-jobs/",
});
// commonディレクトリをwhlファイルに変換してS3にアップロード
new cdk.aws_s3_deployment.BucketDeployment(this, "DeployWheel", {
sources: [
cdk.aws_s3_deployment.Source.asset(
path.join(__dirname, "..", "..", "..", "resources"),
{
bundling: {
image: cdk.DockerImage.fromRegistry("python:3.10"),
command: [
"bash",
"-c",
"pip install --user --upgrade pip && " +
"pip install --user --no-cache-dir build wheel && " +
"python -m build --wheel && " +
"cp dist/*.whl /asset-output/common-0.1-py3-none-any.whl && " +
"rm -rf dist build *.egg-info",
],
user: "root",
},
}
),
],
destinationBucket: this.sysBucket,
destinationKeyPrefix: "common/",
});
}
}
s3.tsではBucketDeploymentを修正しています。resourcesディレクトリをソースとして指定し、Python 3.10のDockerイメージを利用してビルド環境を設定しています。この環境内でpython -m build --wheelコマンドを実行し、プロジェクトのルートディレクトリにある pyproject.tomlファイルを読み込み、pyproject.tomlの内容に基づいて、ビルドプロセスが設定され、wheelファイルを作成します。その後指定された出力ディレクトリにコピーします。
import { Construct } from "constructs";
import * as glue from "aws-cdk-lib/aws-glue";
import * as iam from "aws-cdk-lib/aws-iam";
export interface GlueConstructProps {
envName: string;
projectName: string;
dataSourceBucketName: string;
dataStoreBucketName: string;
sysBucketName: string;
}
export class GlueConstruct extends Construct {
public readonly glueJobName: string;
constructor(scope: Construct, id: string, props: GlueConstructProps) {
super(scope, id);
const glueJobRole = new iam.Role(this, "GlueJobRole", {
assumedBy: new iam.ServicePrincipal("glue.amazonaws.com"),
description: "Role for Glue Job execution",
roleName: `${props.projectName}-${props.envName}-etl-glue-execution-role`,
});
glueJobRole.addToPolicy(
new iam.PolicyStatement({
resources: ["arn:aws:logs:*:*:*:/aws-glue/*"],
actions: [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
],
})
);
glueJobRole.addToPolicy(
new iam.PolicyStatement({
actions: [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"s3:CopyObject",
],
resources: [
`arn:aws:s3:::${props.dataSourceBucketName}`,
`arn:aws:s3:::${props.dataSourceBucketName}/*`,
`arn:aws:s3:::${props.dataStoreBucketName}`,
`arn:aws:s3:::${props.dataStoreBucketName}/*`,
`arn:aws:s3:::${props.sysBucketName}`,
`arn:aws:s3:::${props.sysBucketName}/*`,
],
})
);
this.glueJobName = `${props.projectName}-${props.envName}-glue-job`;
// Glue Jobの定義
new glue.CfnJob(this, "GlueJob", {
name: this.glueJobName,
role: glueJobRole.roleArn,
command: {
name: "pythonshell",
pythonVersion: "3.9",
scriptLocation: `s3://${props.sysBucketName}/glue-jobs/etl_script.py`,
},
executionProperty: {
maxConcurrentRuns: 5,
},
defaultArguments: {
"--TempDir": `s3://${props.sysBucketName}/tmp`,
"--job-language": "python",
+ "--extra-py-files": `s3://${props.sysBucketName}/common/common-0.1-py3-none-any.whl`,
"--S3_OUTPUT_BUCKET": props.dataStoreBucketName,
"--S3_OUTPUT_KEY": `output/`,
},
});
}
}
glue.tsでは--extra-py-filesをcommon-0.1-py3-none-any.whlに修正しています。
dataSourceBucketName: s3Construct.dataSourceBucket.bucketName,
dataStoreBucketName: s3Construct.dataStoreBucket.bucketName,
sysBucketName: s3Construct.sysBucket.bucketName,
- commonZipkey: s3Construct.commonZipAsset.s3ObjectKey,
} as GlueConstructProps);
const stepFunctionsConstruct = new StepFunctionsConstruct(
etl-stack.tsでは先ほどのcommonZipkeyを削除しています。
resourcesフォルダ配下は先ほどから構成を変更しています。common配下に__init__.pyという空ファイルを作成します。空の __init__.py 含めることで、将来的な拡張性を確保しつつ、現在のパッケージ構造を明確に定義します。
resources % tree
.
├── common
│ ├── __init__.py
│ ├── data_processing.py
│ └── get_logger.py
├── glue-jobs
│ └── etl_script.py
└── pyproject.toml
import pandas as pd
import pendulum
from io import StringIO
from common.get_logger import setup_logging
logger = setup_logging()
def get_current_time():
current_time = pendulum.now("Asia/Tokyo")
logger.info(f"Current time: {current_time}")
return current_time
def read_csv_from_s3(s3_client, bucket, key):
logger.info(f"Reading CSV from S3. Bucket: {bucket}, Key: {key}")
response = s3_client.get_object(Bucket=bucket, Key=key)
df = pd.read_csv(response["Body"])
logger.info(f"Successfully read CSV. Shape: {df.shape}")
return df
def write_csv_to_s3(s3_client, df, bucket, key):
logger.info(f"Writing CSV to S3. Bucket: {bucket}, Key: {key}")
csv_buffer = StringIO()
df.to_csv(csv_buffer, index=False)
s3_client.put_object(Bucket=bucket, Key=key, Body=csv_buffer.getvalue())
logger.info("Successfully wrote CSV to S3.")
def calculate_years_since_arrival(arrival_date, reference_date):
return reference_date.diff(pendulum.parse(arrival_date)).in_years()
def process_data(df):
logger.info("Starting data processing")
logger.info(f"Input data shape: {df.shape}")
# 現在の日付を取得
now = pendulum.now()
if "arrival_date" in df.columns:
# 到着からの経過年数を計算
df["years_since_arrival"] = df["arrival_date"].apply(lambda x: calculate_years_since_arrival(x, now))
logger.info("Added years since arrival")
logger.info(f"Processed data shape: {df.shape}")
logger.info("Data processing complete")
return df
data_processing.pyでは、whlファイルを使用する利点である依存関係のあるライブラリ管理を行いたいため、pendulumを用いた処理に修正とライブラリの呼び出し方法をcommon指定に修正しています。
import sys
import pkgutil
- import glob
import boto3
import traceback
- # 動的にZIPファイルを検索し、sys.pathに追加
- zip_files = glob.glob("/tmp/glue-python-libs-*/*.zip")
- for zip_file in zip_files:
- sys.path.append(zip_file)
- print(f"Added {zip_file} to sys.path")
-
- print("Updated sys.path:", sys.path)
def print_importable_modules():
print("--- Importable Python Modules ---")
+ from common.data_processing import process_data, get_current_time, read_csv_from_s3, write_csv_to_s3
+ from common.get_logger import setup_logging
etl_script.pyではzipファイルに関連する処理を削除しています。またライブラリの呼び出し方法をcommon指定に修正しています。
[build-system]
requires = ["setuptools>=45", "wheel", "build"]
build-backend = "setuptools.build_meta"
[project]
name = "common"
version = "0.1"
dependencies = ["pendulum"]
[tool.setuptools.packages.find]
where = ["."]
include = ["common*"]
新たにpyproject.tmlを作成しています。Python プロジェクトの設定ファイルで、python -m build --wheelコマンドはこのファイルを参照してビルドを行います。
- build-system : ビルドに必要なツールとバックエンドを指定
- project : パッケージ名、バージョン、依存関係を定義
- tool.setuptools.packages.find : パッケージに含めるファイルを指定
最初はsetup.pyを用いた実装をしていましたが、以下の記事をみて、pyproject.tmlが推奨されていたので修正しました。
実行
デプロイは先ほどと同様のため、スキップしています。EventBridge TriggerでGlue Jobが実行され、自作関数を使用できました。
--- Importable Python Modules ---
awsglue
blueprint-run-script
runscript
_time_machine
common
dateutil
pendulum
:
:
yaml
yarl
2024-07-10T13:28:34.894Z [INFO][data_processing.py][read_csv_from_s3:16] Reading CSV from S3. Bucket: cm-kasama-dev-data-source, Key: input/animal_info.csv
2024-07-10T13:28:34.997Z [INFO][data_processing.py][read_csv_from_s3:19] Successfully read CSV. Shape: (5, 7)
2024-07-10T13:28:34.997Z [INFO][etl_script.py][main:44] Processing data... [INFO][data_processing.py][process_data:36] Starting data processing [INFO][data_processing.py][process_data:37] Input data shape: (5, 7)
2024-07-10T13:28:35.010Z [INFO][data_processing.py][process_data:45] Added years since arrival [INFO][data_processing.py][process_data:47] Processed data shape: (5, 8)
2024-07-10T13:28:35.011Z [INFO][data_processing.py][process_data:48] Data processing complete
2024-07-10T13:28:35.014Z [INFO][data_processing.py][get_current_time:11] Current time: 2024-07-10 22:28:35.010674+09:00
2024-07-10T13:28:35.014Z [INFO][etl_script.py][main:50] Writing processed data to s3://cm-kasama-dev-data-store/output/output_2024-07-10-22-28-35.csv [INFO][data_processing.py][write_csv_to_s3:24] Writing CSV to S3. Bucket: cm-kasama-dev-data-store, Key: output/output_2024-07-10-22-28-35.csv
2024-07-10T13:28:35.143Z [INFO][data_processing.py][write_csv_to_s3:28] Successfully wrote CSV to S3.
2024-07-10T13:28:35.144Z [INFO][etl_script.py][main:53] ETL process completed successfully
output.csvも加工されたカラムが出力できました。
animal_id,animal_name,species,weight_kg,age_years,habitat,arrival_date,years_since_arrival
1,Luna,Tiger,120,5,Savanna,2018-03-15,6
2,Bella,Elephant,2500,8,Jungle,2015-07-22,8
3,Max,Lion,190,6,Savanna,2017-11-30,6
4,Daisy,Giraffe,800,4,Savanna,2019-01-05,5
最後に
共通関数が使用できることで、Glue Jobを何本か実装する際にlogging処理などをまとめられるので、用途は結構あると感じました。少しでもどなたかのお役に立てれば幸いです。









